大模型算法实习八股
一般来说,开发岗位的算法面试是不会出题要求面试者临时设计一个数据结构来解决某个问题,大多数时候只是要求面试者能够熟练掌握常见的数据结构及其实现、能够说出这种数据结构的优缺点即可。
大模型架构
原始 Transformer
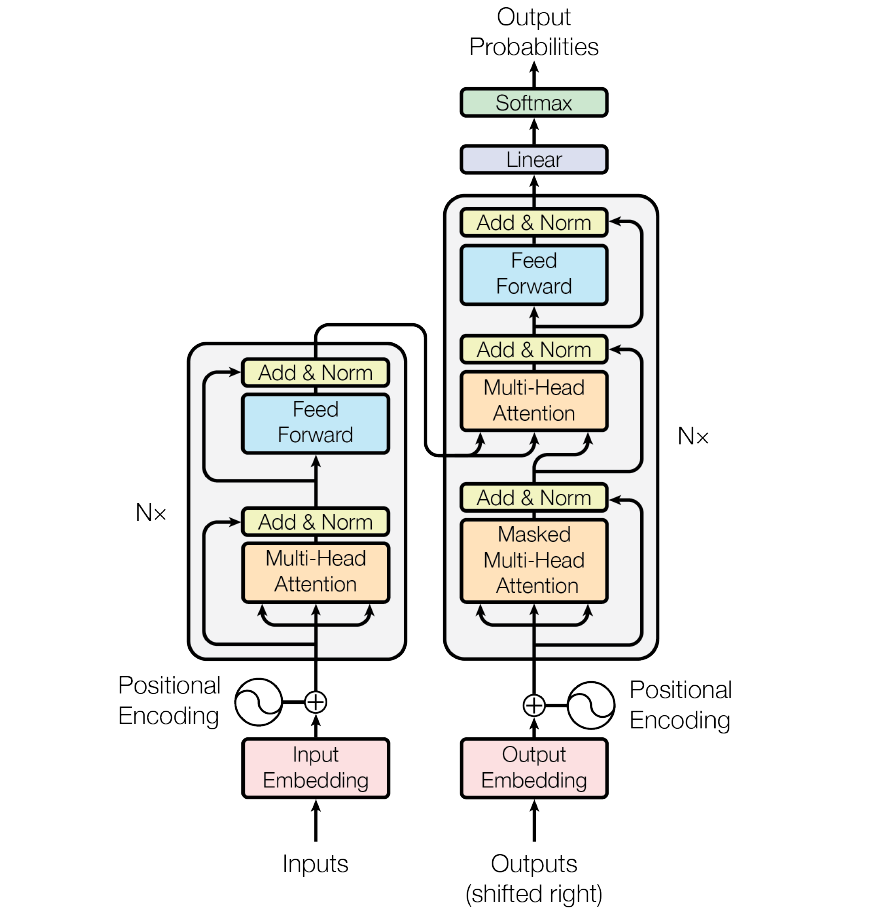
分词方式
字节对编码 BPE
本质上是subword作为词表,只不过是优先合并出现频率高的字符,直到词表大小合适或者最高词频为1
注意力机制
注意力评分函数
加性注意力评分函数
加性注意力评分函数可以看作,将查询和键连结起来后输入到一个多层感知机(MLP)中, 感知机包含一个隐藏层,其隐藏单元数是一个超参数ℎ。 通过使用tanh作为激活函数,并且禁用偏置项,缩放点积注意力评分函数
为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 将点积除以
Summary:
- 加性注意力和缩放点积注意力计算复杂度接近,但矩阵乘法有非常成熟的加速实现,所以缩放点积注意力的计算效率更高。
- 在d(注意力矩阵的维度)较小时,加性和缩放点积注意力效果接近,但随着d的增大,加性注意力开始显著超越缩放点积。原因是极大的点积值将整个 softmax 推向梯度平缓区,使得收敛困难,所以缩放点积注意力需要除以
。
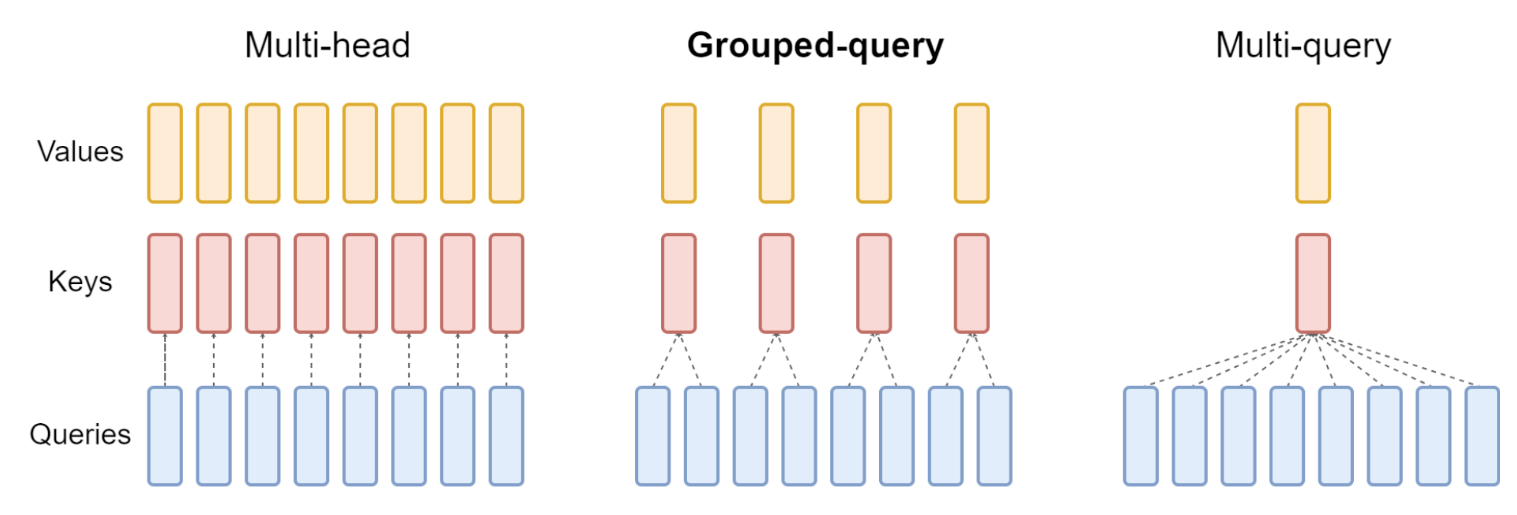
多头注意力机制 MHA
QKV 三部分有相同数量的头,且一一对应。每次做 Attention,head_i 的 QKV 做好自己的运算就可以,输出时各个头加起来就行
多查询注意力机制 MQA
让 Q 仍然保持原来的头数,但 K 和 V 只有一个头,相当于所有的 Q 头共享一组 K 和 V 头,所以叫做 Multi-Query 了。
分组查询注意力机制 GQA
是 MHA 和 MQA 的折衷方案,既不想损失性能太多,又想获得 MQA 带来的推理加速好处。具体思想:不是所有 Q 头共享一组 KV,而是进行分组,一定头数 Q 共享一组 KV
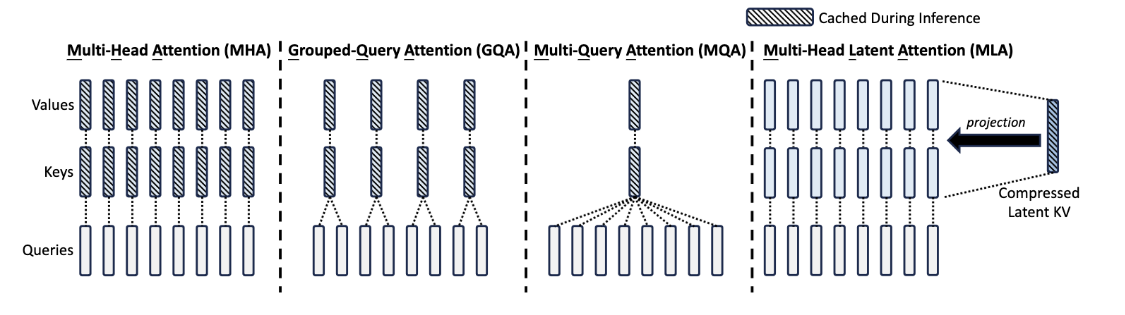
Multi-Head Latent Attention
MLA是为了解决在推理时KV Cache占据空间过大的问题
Normalization
Batch Norm
同一个位置token下,同一批batch下不同条数据进行标准化
Layer Norm(pre Norm (用的更多,训练起来更方便,但是没有post Norm上限高)and post Norm)
同一条数据中,不同位置token进行标准化
RMS Norm
RMSNorm和LayerNorm的主要区别在于RMSNorm不需要同时计算均值和方差两个统计量,而只需要计算均方根 Root Mean Square 这一个统计量,RMS Norm认为,Layer Norm成功的原因是
re-scaling,因为方差Var计算的过程中使用了均值Mean,因此RMS Norm不再使用均值Mean,而是构造了一个特殊的统计量RMS代替方差Var。
为什么 LN 比 BN 更适用于 Transformer 类模型呢,这是因为 transformer 模型是基于相似度的,把序列中的每个 token 的特征向量进行归一化有利于模型学习语义,第一步调整均值方差时,相当于对把各个 token 的特征向量缩放到统一的尺度,第二步施加
pre-norm 和 post-norm的区别
pre-norm:训练更加稳定, 在训练稳定和收敛性方面有明显的优势
post-norm:训练不稳定,但是潜在效果会更好,对训练不稳定,梯度容易爆炸,学习率敏感,初始化权重敏感,收敛困难。好处是有潜在效果上的优
归一化 | 标准化 的概念区分
归一化
均值归一化
标准化
单位化
RoPE 位置编码
绝对位置编码
- 训练式位置编码
- sin位置编码
绝对位置编码的缺陷在于无法长度外推
RoPE 是相对位置编码,本质上通过让高维向量旋转 的方式将相对位置信息加入到 词向量中,具体做法是词向量乘以一个旋转矩阵,旋转矩阵中有相对位置信息
$$
$$
激活函数
SoftMax
softmax一般用于多分类的结果,一般和one-hot的真实标签值配合使用,大多数用于网络的最后一层
Sigmoid
sigmoid是原本一种隐层之间的激活函数,但是因为效果比其他激活函数差,目前一般也只会出现在二分类的输出层中,与0 1真实标签配合使用
ReLU
线性整流函数(ReLU函数)的特点:
- 当输入为正时,不存在梯度饱和问题。
- 计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比Sigmoid函数和tanh函数更快。
- Dead ReLU问题。当输入为负时,ReLU完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,Sigmoid函数和tanh函数也具有相同的问题
- ReLU函数的输出为0或正数,这意味着ReLU函数不是以0为中心的函数。
Silu
SwiGLU 激活函数是Shazeer 在文献中提出,并在PaLM等模中进行了广泛应用,并且取得了不错的效果,相较于ReLU 函数在大部分评测中都有不少提升。可以看做是平滑的ReLU激活函数。
Tanh
双曲正切函数是双曲函数的一种。双曲正切函数在数学语言上一般写作tanh \tanhtanh。它解决了Sigmoid函数的不以0为中心输出问题,然而,梯度消失的问题和幂运算的问题仍然存在
损失函数
KL散度
KL散度度量的是同一个随机变量的两个单独分布之间的距离,而非针对不同随机变量的
交叉熵损失函数
分类为什么用交叉熵而不用MSE?
MSE作为损失函数有梯度消失的问题
L1和L2正则化约束
L1是参数绝对值之和加到loss上,L2是平方和加到loss上
优化器
Adam
SGD
文本大模型
Llama3 架构
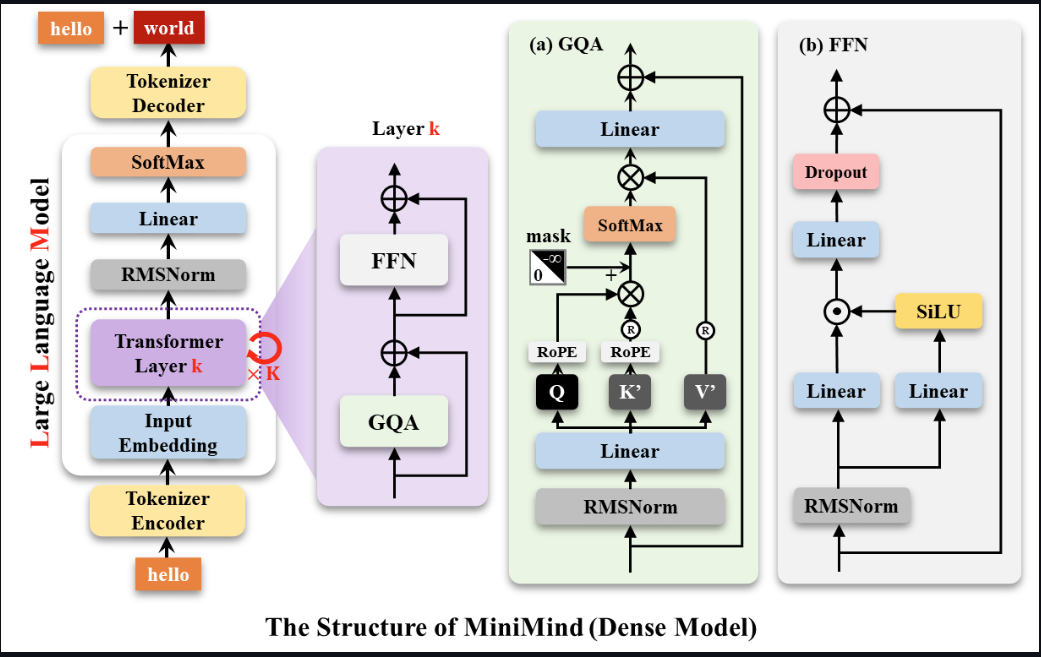
残差网络的优点:
- 防止梯度消失
- 特征重用
- 能够让模型的层数变得很多
为什么decoder only架构成为主流?
首先淘汰encoder only的结构,因为masked language model预训练方式不擅长做生成任务
decoder only在工程上有更高的效率性,可以KV-cache,并且zero-shot的能力要更强
在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
FFN层为什么先升维再降维
升维。其主要作用是拟合一个更高维的映射空间,从而提升模型的表达能力和拟合精度。
降维。其主要作用是还原维度,限制计算复杂度。
多模态大模型
Vit架构
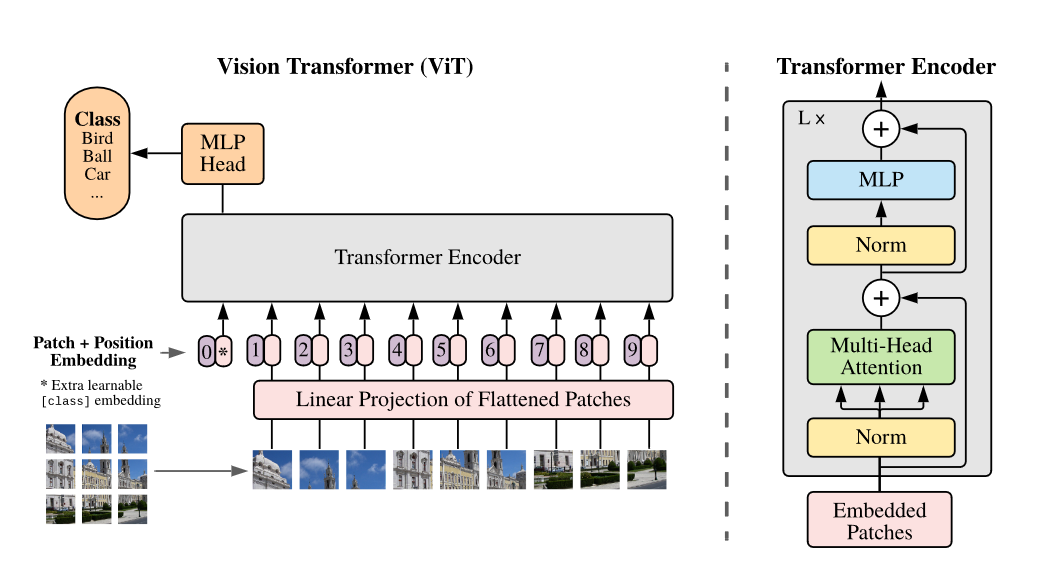
- Patch Embedding的作用是将一个CV问题通过切块和展平转化为一个NLP问题
总体架构
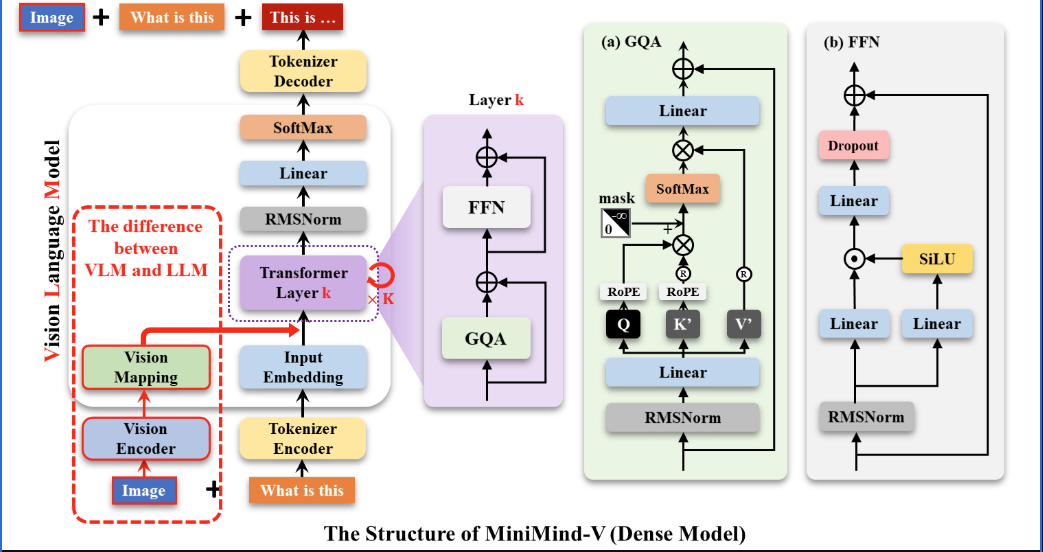
Vision Mapping 就是用图片token将
MOE架构
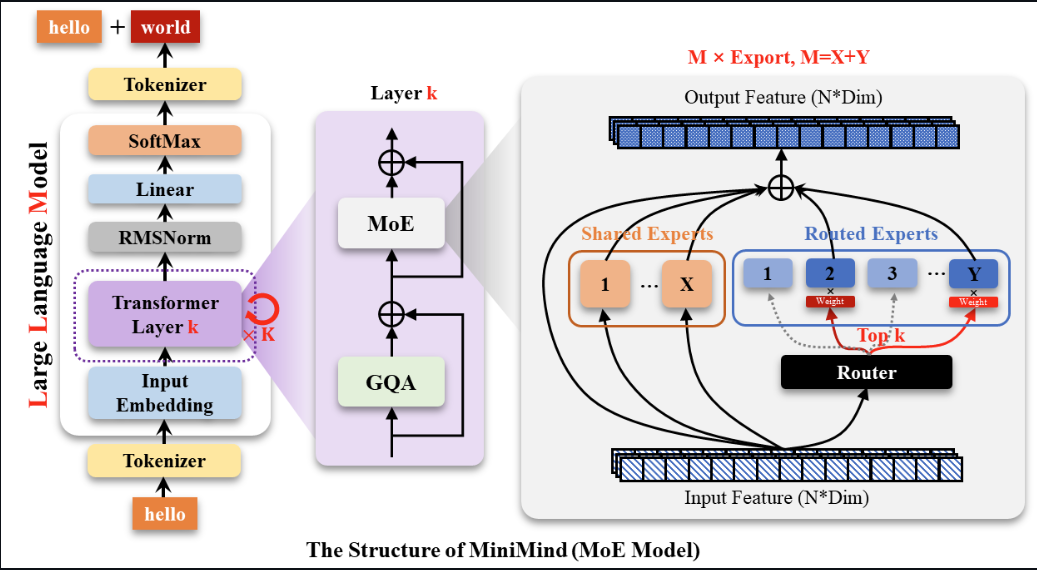
Gate网络和专家选择机制
- 计算匹配得分
Gate 网络通过线性变换计算每个 token 与所有路由专家的兼容性得分。得分反映了 token 与各专家“契合”的程度。 - 选择 Top-K 专家
基于得分,Gate 网络为每个 token 选择 Top-K 个最合适的路由专家。在 DeepSeek‐V3 中,每个 token 通常选择 8 个路由专家(在一些实现中还可能对跨节点路由做限制,如最多路由到 4 个不同节点),从而只激活极少数专家进行计算。 - 专家处理与加权聚合
被选中的专家各自对 token 进行独立处理(一般采用一个轻量级的前馈网络,类似于 Transformer 中的 FFN 模块),产生各自的输出。最终,这些专家的输出会根据 Gate 网络给出的权重进行加权聚合,再与共享专家的输出进行融合,形成当前 MoE 层的最终输出表示。
大模型微调
SFT微调算法
LORA
A矩阵参数初始化为正态分布,B矩阵参数初始化为0
- 如果B和A全部初始化为零矩阵,缺点是很容易导致梯度消失。
- 如果B和A全部正态分布初始化,那么在模型训练开始时,就会容易得到一个过大的偏移值△W,从而引起太多噪声,导致难以收敛。
QLORA
在反向传播过程中,QLoRA 将预训练的权重量化为 4-bit,并使用分页优化器来处理内存峰值。
Prompt-Tuning
Prompt Tuning设计了一种prefix prompt方法,即在模型输入的token序列前添加前缀prompt token,而这个前缀prompt token的embedding是由网络学到。
Prompt Tuning可以看做token已经确定,但是embedding是可以学的。它相当于仅用prompt token的embedding去适应下游任务,相比手工设计或挑选prompt,它是一种Soft的prompt(软提示),
Prefix-tuning
Prefix tuning为ll层的Transformer Layer的每层多头注意力的键和值都配置了可学习的prefix vectors.
Prefix-Tuning可以算是Promot Tuning的一个特例(Promot Tuning只在输入侧加入可学习的Prefix Prompt Token)
P-Tuning
- Prefix Tuning 是将额外的 embedding 加在开头,看起来更像是模仿 Instruction 指令;而 P-Tuning 的位置则不固定。
- Prefix Tuning 通过在每个 Attention 层都加入 Prefix Embedding 来增加额外的参数,通过 MLP 来初始化;而 P-Tuning 只是在输入的时候加入 Embedding,并通过 LSTM+MLP 来初始化。
P-Tuning V2
相比 Prompt Tuning 和 P-tuning 的方法, P-tuning v2 方法在多层加入了 Prompts tokens 作为输入
Adapter Tuning
Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。Adapter即插入的FF up + FF Down(其实就是一个MLP)
缺点:需要修改原有模型结构,同时还会增加模型参数量。
微调框架
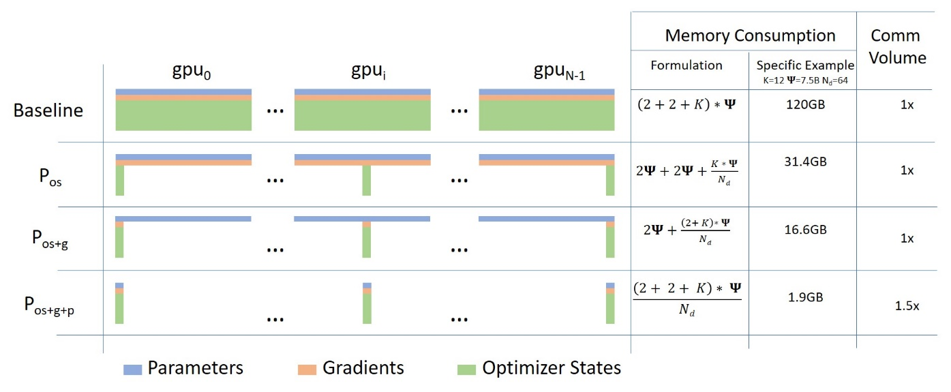
Deepspeed
显存=模型参数+梯度+优化器状态+中间激活值
zero-0: 不采用任何内存优化方案,也就是普通DDP
zero-1:将optimer需要存储的值切分到各个显卡上
zero-2:将优化器状态和梯度都划分到不同的设备上
zero-3:将模型参数、优化器状态和梯度都分到不同设备上
Megatron-LM
- 数据并行
- 张量并行
- 流水线并行
大模型蒸馏
白盒蒸馏
黑盒蒸馏
大模型强化学习微调
为什么RLHF有效
- 多样性假设:对于同一个指令或者问题,模型应该能够产生多种多样的答案,而不是仅仅局限于SFT数据中对应的那一句回答
- 负样本均衡问题:对于SFT阶段,所有的数据都是精挑细选的高质量数据,也就是所谓的正样本,而我们都知道,训练模型时正负样本均衡才更有助于模型的泛化性,而SFT阶段没有向模型展示过任何负样本,而RLHF允许我们向模型展示负样本
- RLHF有助于解决模型幻觉
RLHF
强化学习微调需要用到四个模型,Actor模型、Reference模型、Critic模型、Reward模型
其中Actor模型是要微调的大模型,Reference模型是参数冻结的Base大模型,与Actor模型初始参数相同,Critic模型是用来评估Actor模型生成回答的整体好坏性,Reward模型是用来产生即时奖励的模型,初始的Critic模型与Reward模型是同一个模型,只不过Critc模型会与Actor模型一起进行参数更新,而Ref模型和Reward模型的参数是全程冻结的,Ref模型参数冻结是因为需要Ref模型的输出来作为一个参考,防止Actor模型跑偏。Reward模型在人类偏好训练完成之后便保持了与人类偏好一致,所以参数不能更新,否则将无法使Actor模型的输出与人类偏好对齐。Critic模型输出的奖励值一开始与Rewar模型一致,但是Critic模型需要不断估计在不同状态下Actor模型输出的好坏,所以需要随着数据不断进行参数更新,使自身对价值的估计与状态相契合。
参数更新需要用到loss, Actor模型的loss来自于其他三个模型,首先Ref模型将提供一个限制Actor模型跑偏的loss,Reward模型将提供一个一个token生成时的即时奖励loss, Critic模型提供一个当前token生成对未来长远影响的loss,一共三个loss,组成Actor模型的最终loss。这个最终loss的最终目标是想要让Actor模型在生成的意思没有太大变化的同时,使用符合人类偏好的文字来表达。
PPO
DPO
使用DPO数据,同一个问题,一个接受的答案,一个拒绝答案
DPO loss 计算:- Sigmoid((Actor模型在接受答案的概率-Actor模型在拒绝答案上的概率)- (Ref模型在接受答案上的概率-Ref模型在拒绝答案上的概率))
或者可以说 (Actor模型在接受答案的概率-Ref模型在接受答案上的概率)- (Ref模型在拒绝答案上的概率-Actor模型在拒绝答案上的概率)
也就是说 loss 使得Actor模型的生成答案相比较于Ref模型 更靠近接受答案, 更远离拒绝答案
GRPO
不使用优势,采用多次采样,近似得到baseline
为什么GRPO一开始loss为0?
一开始actor model 和ref model 的KL散度是0,在一开始时损失函数等于
倍的平均KL散度,所以loss一开始是0 为什么Loss的更新方向是增长方向的,不是(策略)梯度下降吗?
一开始训练的时候,actor mode 参数更新之后,与ref model不一样之后,KL散度开始增加,所以loss变大
GRPO能直接使用在较小参数的模型上训练微调吗?
GRPO 多次采样是同一个输入,采样不同输出
大模型推理
推理常见参数
- Greedy Search
- Beam Search
- tok-k
- top-p
- temperature:当T=1时,输出分布将与标准softmax输出相同。T的值越大,输出分布就越平滑,T的值越小,输出分布越陡峭
- repetition_penalty
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
LLM出现复读机现象?
原因:
- 由于贪婪策略,LLM趋向于提高重复先前句子的概率
- 而且这种现象会愈演愈烈,自我强化
解决办法:
- 构造伪数据,设计惩罚因子来惩罚训练
- 解码策略调整,使用惩罚重复参数,beam search、调整温度T参数
推理优化技术
KV Cache
每一步计算注意力分数的时候,只需要新token的Q与以往的的K计算得到注意力分数,然后与之前所有的V进行计算得到最终结果,所以只有新的Q是需要新的token的Q,而K和V之前计算过的可以重复利用,所以在每一步计算的时候将K和V保存下来在下一步计算,便可以减少计算量,达到加速效果。
Flash Attention
动机:Attention机制计算 对于长序列 不友好
将输入分块计算,然后合并重新计算
https://mp.weixin.qq.com/s/P_21MWC82l945jCWuUAD_A
大模型量化
float16, float32,bfloat16

从左到右分别是,符号位S,指数E,尾数M, R是基数(2或10)
range越大表示范围越大,precision越大表示精度越高
大模型给定参数多少B,计算模型大小多少GB 和 显存占用多少GB?
模型大小:1B 约等于 4G 1b=1000M=4000MB=4GB 在float32的情况下 因为32bit=4byte
显存占用:总显存=4GB(参数)+4GB(梯度)+8GB(优化器状态)=16GB
AWQ
按照重要性来选择性量化某些值
GPTQ
按照层来选择性量化某些层
思维链推理
o1发布后,国内陆续发布了很多类o1模型,比如deepseek-r1、kimi-math、macro-o1、qwq等等
- 树搜索派系,主要使用树搜索+multi-agent合成数据
- 蒸馏派系,主要通过各种jail-break攻破o1的思维链展示限制、爬deepseek-r1以及使用qwen-qwq刷数据蒸馏。
超长上下文扩展
线性位置插值法扩展
通过线性缩小输入位置索引以匹配原始上下文窗口大小,而不是超出训练上下文长度进行外推,这样可以减小注意力机制中相对位置的影响,帮助模型更容易适应扩展后的上下文窗口。
需要重新训练
动态插值法
利用神经正切核 (NTK) 理论,设计非线性位置编码插值方案,改变基数而不是缩放比例,使不同位置可区分,避免线性插值的问题。
Yarn方法
Yarn 方法对不同频率的正弦波进行不同程度的插值:
- 对高频正弦波几乎不进行插值,保留细微位置信息。
- 对低频正弦波进行接近线性的插值,保留位置大体信息。
- 中频正弦波进行渐变的插值。
大模型测评
模型幻觉
产生的原因
- 大模型对自己的输出缺乏因果关系的判断
- LLM内部知识与人类标注的知识的不匹配,LLM内部知识不包含人类标注的知识时,模型就会产生幻觉
解决方案
- 让模型能够给出自己回答的依据、来源出处等(感觉是Cot的开端
- 强化学习,因为强化学习在给奖励是只是给出答案1比答案2好,并不给出具体原因和好的程度,所以能够让LLM自己探索出一条属于自己理解的道理
模型融合
Task Vector
TIES
第二步的方向选择上是如何选择的?
TIES-BT
Fuse
不拘泥于必须同一架构,主要融合多个模型的输出vocab概率分布,然后将融合后的概率分布作为target计算loss+clm的loss一起去train模型
Agent技术
面对 文本长度超过模型输入长度的情况,该怎么解决?