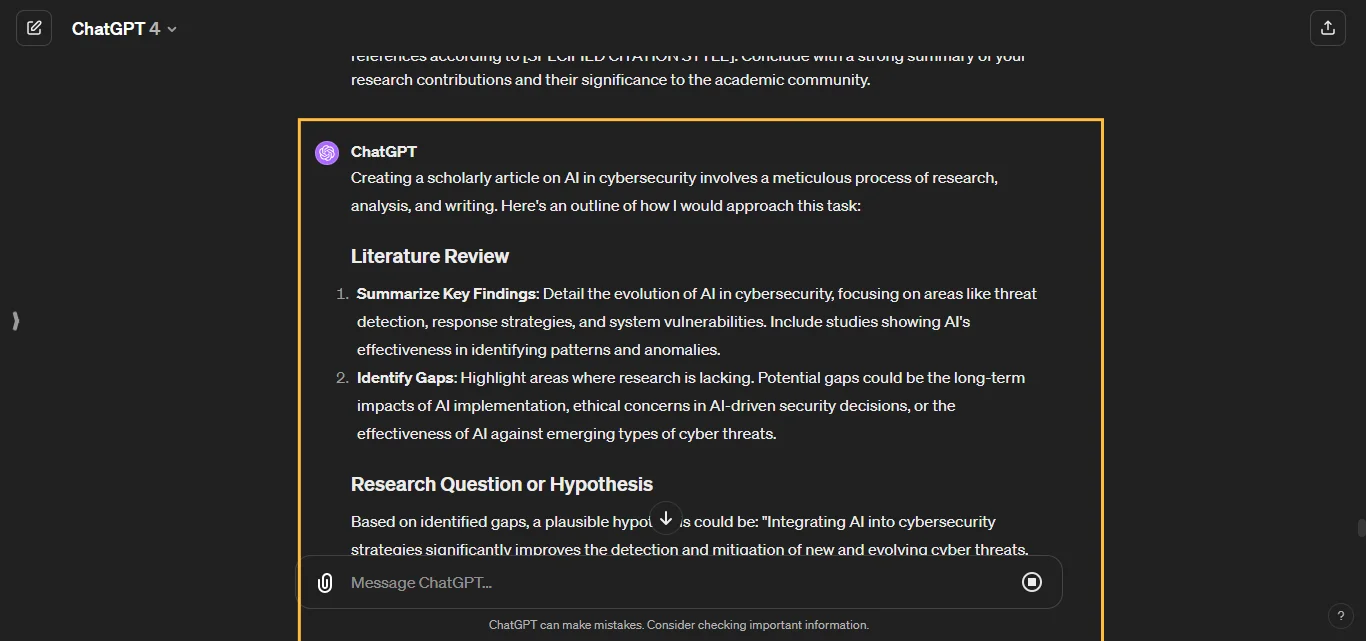
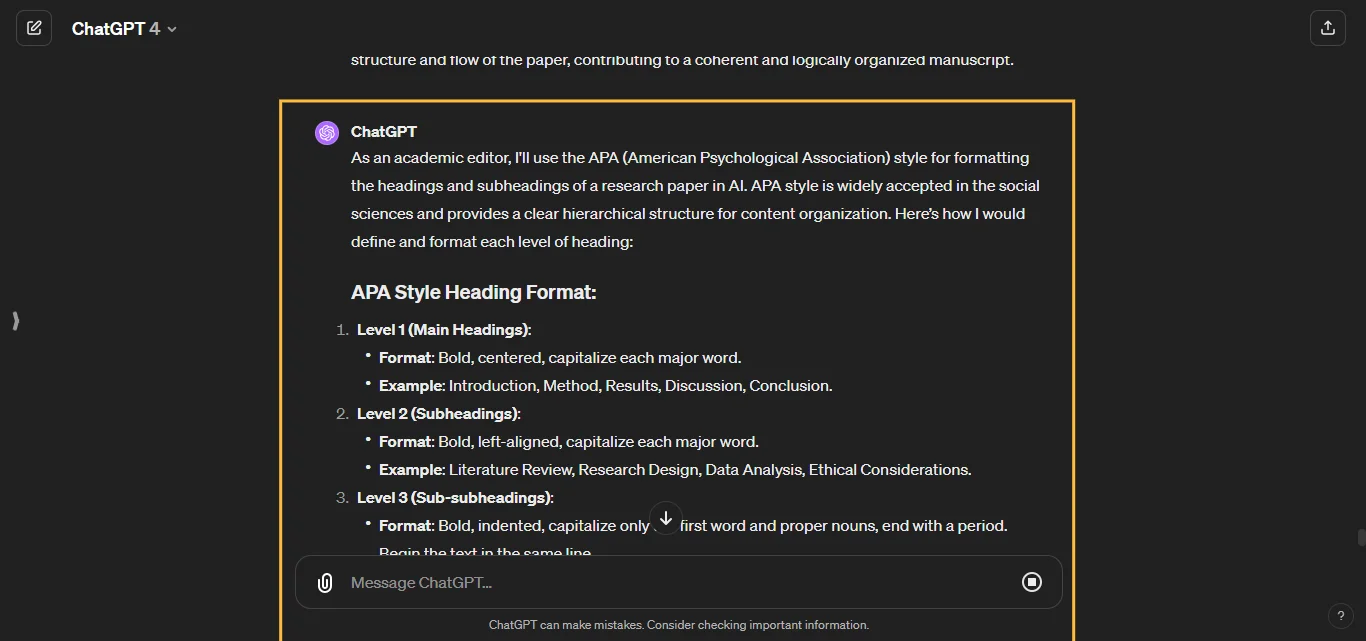
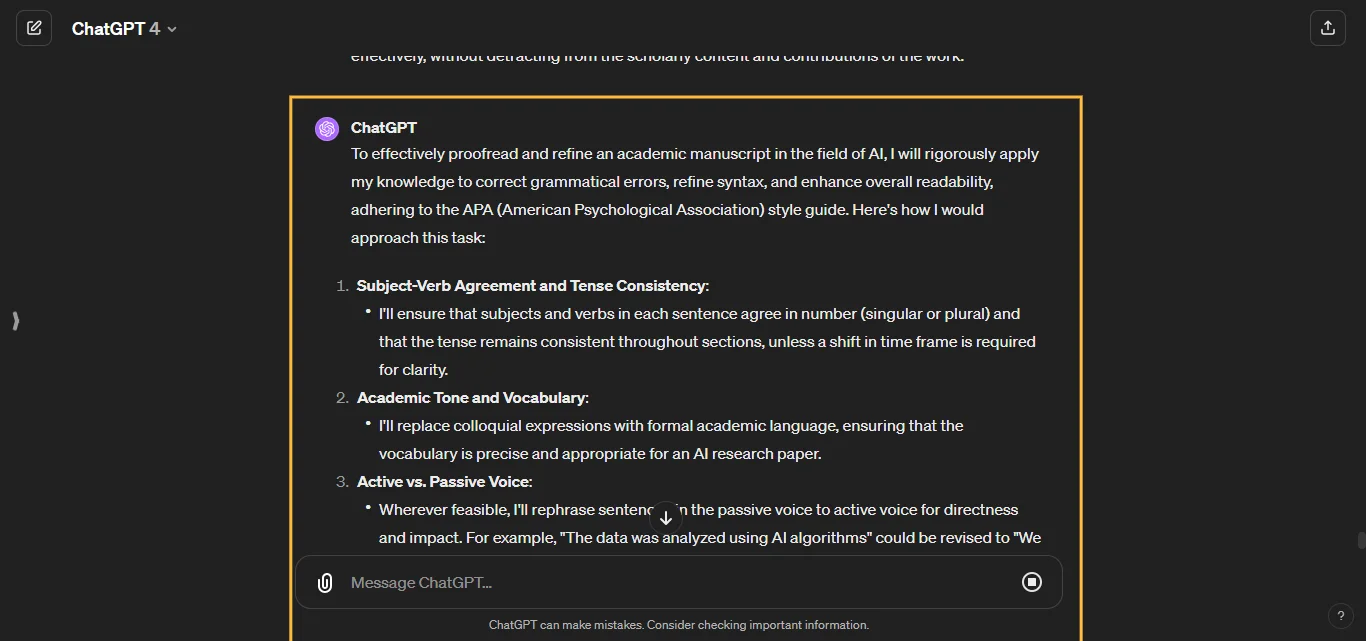
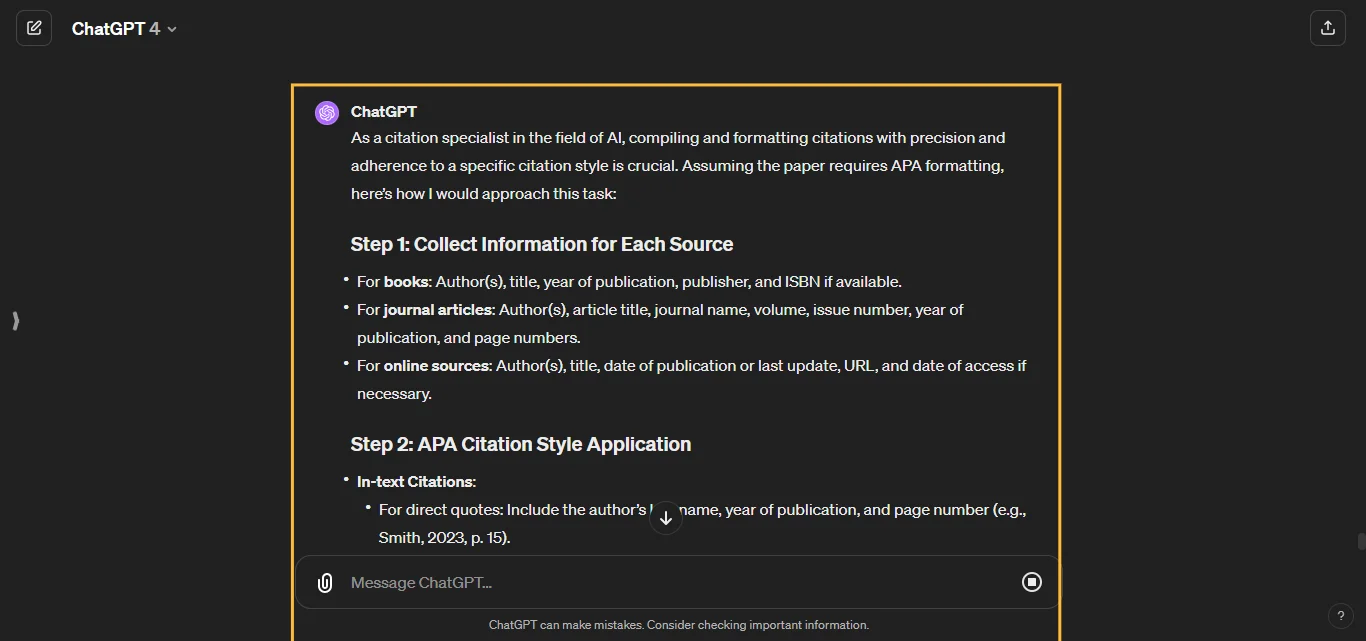
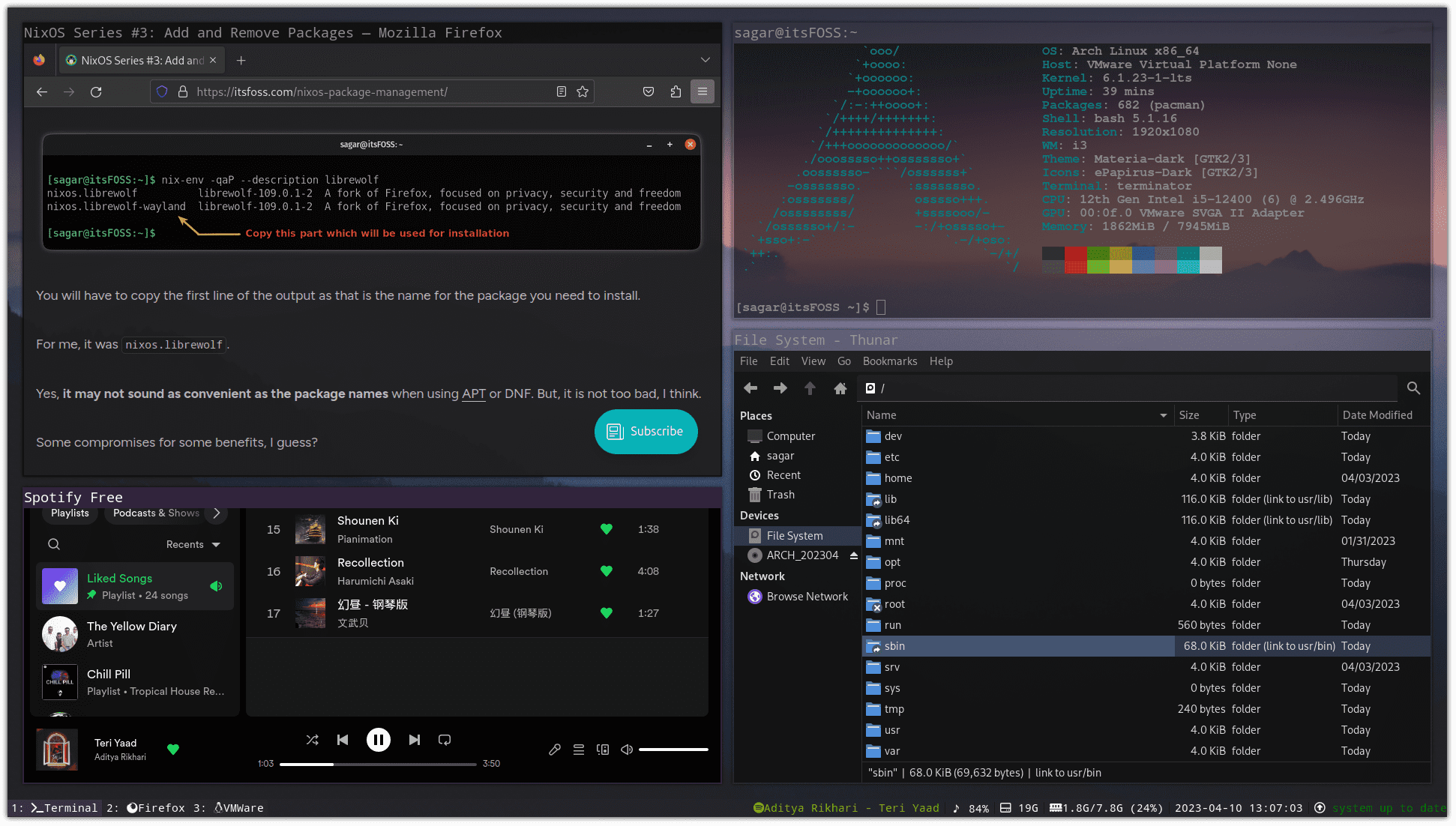
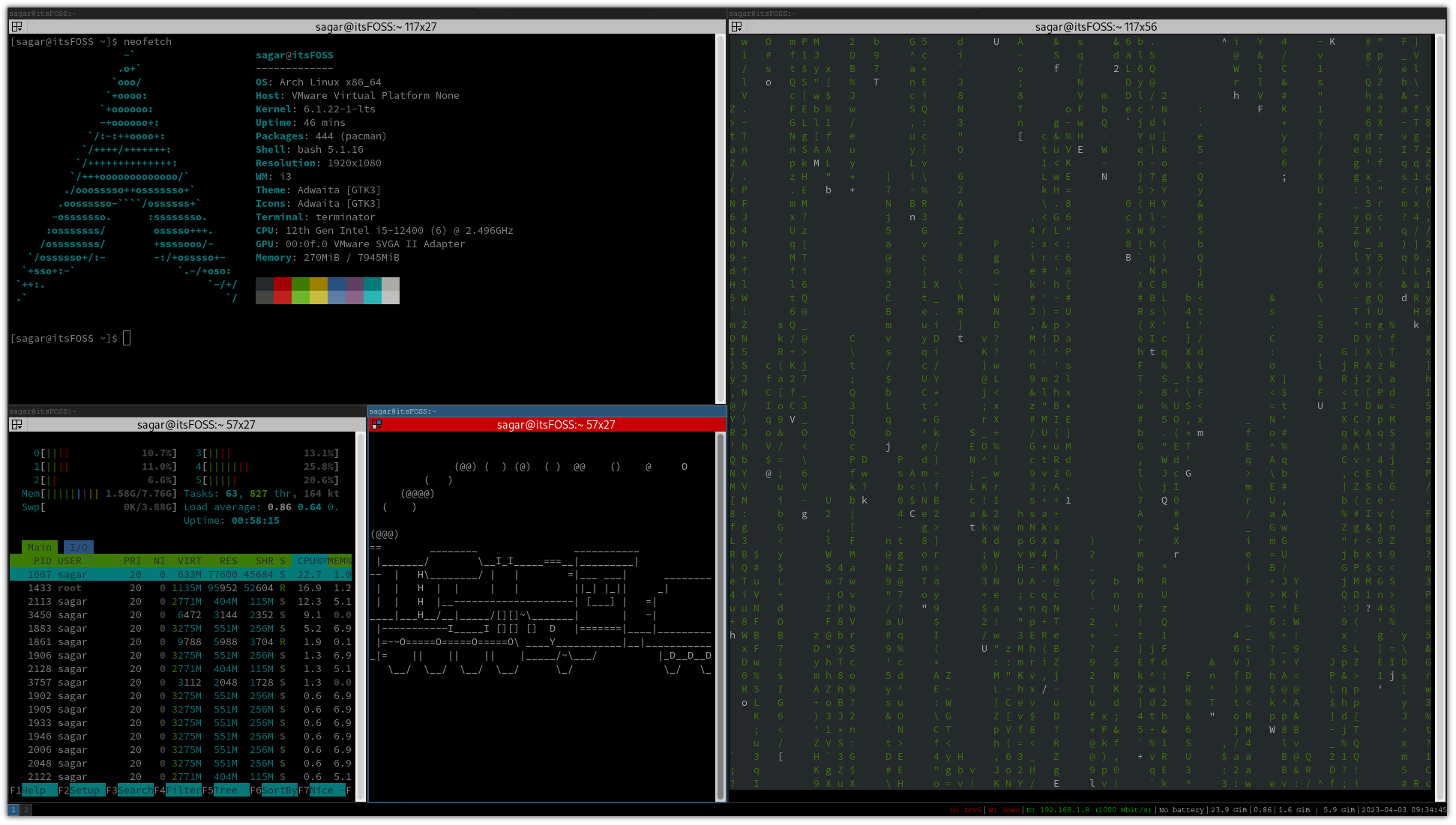
Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. The recent QAC methods introduce Natural Language Generation to generate the completions for user input.
However, NLG (Natural Lagnuage Generation) methods ususally output unsense or wrong words without controll. Moreover, A serious drawback of generative methods is that they can produce an ether effect. It severely affected the performance of the generative methods.
We proposed a framework that controls the generation of queries using prompt learning methods, thereby making the generative methods controllable. This framework consists of three parts: the control module, the prompt module, and the generation module. The control module generates a prompt vector endowed with implicit features, then the prompt module ingests the prompt vector and user input into the generation module, and ultimately, the generation module generates the query under control.
We trained and tested our model on the Meituan dataset and the AOL dataset. The outcomes reveal that the framework we proposed can elevate the accuracy of queries while mitigating the incoherence of queries.
在QAC场景中,我们将问题转换为自然语言处理的问题。因为用户的输入和生成都是自然语言,即$I={i_1,i_2 \cdots i_n}$,$G={g_1,g_2 \cdots g_n}$,其中$i$和$g$都表示具体的字符token,所以$G=f( I )$可以看作一个自回归问题,即$g_n=f( i_1,i_2, \cdots,g_{n-2},g_{n-1})$。
Query Auto-completion is a technology that uses users’ minimal input to generate possible desired results for them, thereby saving them time during the search process. Assuming $I$ represents user input, $G$ represents completed results, and $u$ represents user information, then $G=f(I)$ represents generating results completely utilizing user input, while a more personalized generation is $G_p=g(I,u)$.
In the QAC scenario, we convert the problem into a natural language processing problem. Since both user input and generated results are natural language, namely $I={i_1,i_2 \cdots i_n}$ and $G={g_1,g_2 \cdots g_n}$ where $i$ and $g$ represent specific character tokens, therefore $G=f(I)$ can be regarded as an autoregressive problem, namely $g_n=f(i_1,i_2, \cdots,g_{n-2},g_{n-1})$.
First, we introduce and explain the overall architecture of the framework, which includes three parts: the generation module, the prompt module, and the control module. The generation module is a decoder architecture that predicts the next token and generates text. It typically uses a pre-trained model like GPT. To enable control over the generation effect of the generation module, we use prompt learning methods for control. This means adding a prompt vector to the input of the generation module before generating the text. The prompt vector can provide hints to the model, which is the role of the prompt module. The prompt vector generated in the prompt module is produced by the control module through learning from historical data with controlled purpose labels. This generates a prompt vector with controlling effects.
The input to the control module is the personal feature information of the user and the user’s historical data, and the output is the probability of the user performing a click behavior. Whether the user clicks on the generated words represents the user’s preferences. The model uses the Bert model because the Bert model has deep semantic understanding capabilities and can perform deep semantic understanding and feature extraction on the user’s historical behavioral data. To reflect the controlling effect of the control module, in addition to letting the control module generate high-dimensional feature vectors reflecting user preferences, we also consider that the generative model has a severe Matthew effect phenomenon. Because the generative model is essentially a word probability prediction model, the generative model will predict tokens that appear frequently in the training set with a higher probability. Therefore, in addition to controlling the generation of user preference-conforming results, the control module can also control the Matthew effect of the generative model.Therefore, the output of the Bert model in the control module will be input to two multi-layer neural network classifiers for multi-task learning. One classifier is used to distinguish whether the user performs a click, and the other classifier is used to distinguish whether the user is more likely to click on the generated results of low-frequency words. By modeling the user’s personal information and historical behavior data, the control module can extract a feature vector representing the user’s preferences.
Authors made several expiations for their experiment results, but from the results, it contradicts what authors explained.
In addition, authors observed the contradict result when comparing soft prompt and hard prompt, the explanation was not quite convincible.
Selected architecture is not well motivated compared to similar more flexible approaches like RAG
missed an important span of work that would have beeen totally relevant for the presented use-case
Learning to Write with Cooperative Discriminators
This paper is not well-written and not presented effectively in appropriate format. Some typos are found and also the presentation of figures (like Figure 3) can be improved.
There are some typos in the paper, i.e. in section 3.2 first paragraph, Figure index was missing.
实验问题
Since this is a framework, authors should present more variety datasets to prove this framework work on different domains and datasets, only one specific domain which cannot persuade audience to believe this framework will work for other domains or tasks.
experiments section heavily focuses on different variations of the same method
designed architecture is not flexible and would require retraining given changes in base models
outdated generative model (GPT2) in the experiments make the reader wonder what would be the results with more capable and versatile generative models
failed to showcase the flexibility of the approach: flexibility is cited as an advantage of the approach, but not highlighted in the experiments
More recent baselines can be chosen. The paper lacks comparisons and discussions with widely-known baselines in the field, which hinders the assessment of the novelty and performance of UCTG.
This paper is not well-written and not presented effectively in appropriate format. Some typos are found and also the presentation of figures (like Figure 3) can be improved.
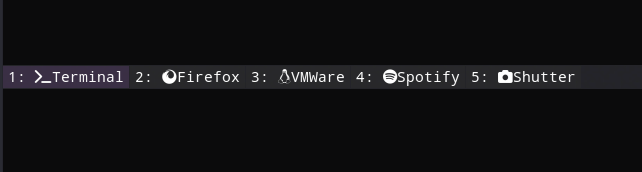
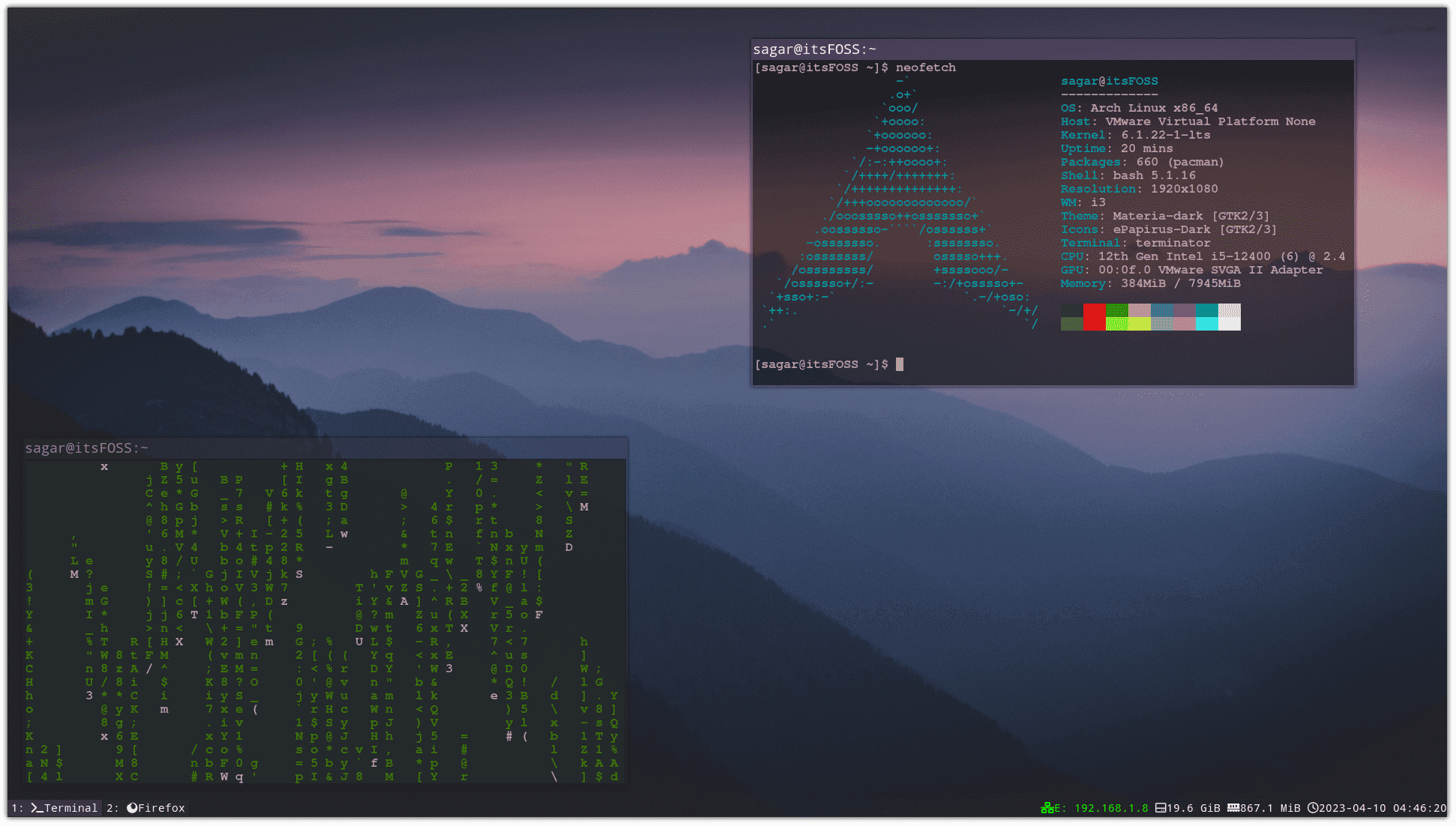
# 定义默认工作区的名称,稍后我们将在其中配置键绑定。 # 我们使用变量来避免在多个地方重复使用名称。 set $ws1 "1: Terminal" set $ws2 "2: Firefox" set $ws3 "3: VMWare" set $ws4 "4: Spotify" set $ws5 "5: Shutter" set $ws6 "6" set $ws7 "7" set $ws8 "8" set $ws9 "9" set $ws10 "10"
# 定义默认工作区的名称,稍后我们将在其中配置键绑定。 # 我们使用变量来避免在多个地方重复使用名称。 set $ws1 "1: Terminal" set $ws2 "2: Firefox" set $ws3 "3: VMWare" set $ws4 "4: Spotify" set $ws5 "5: Shutter" set $ws6 "6" set $ws7 "7" set $ws8 "8" set $ws9 "9" set $ws10 "10"
不要担心它看起来可怕!
完成后,使用 Mod + e 退出 i3,然后再次登录以应用你刚刚所做的更改。
我的效果如下图所示:
字体看起来太小?是时候解决这个问题了!
在 i3 中更改标题窗口和状态栏的字体
首先,让我们安装新的字体(我将在这里使用 Ubuntu 字体)。
要在 Arch 上安装 Ubuntu 字体,请执行以下操作:
1
sudo pacman -S ttf-ubuntu-font-family
如果你使用的是 Ubuntu,你已经安装了这些字体!
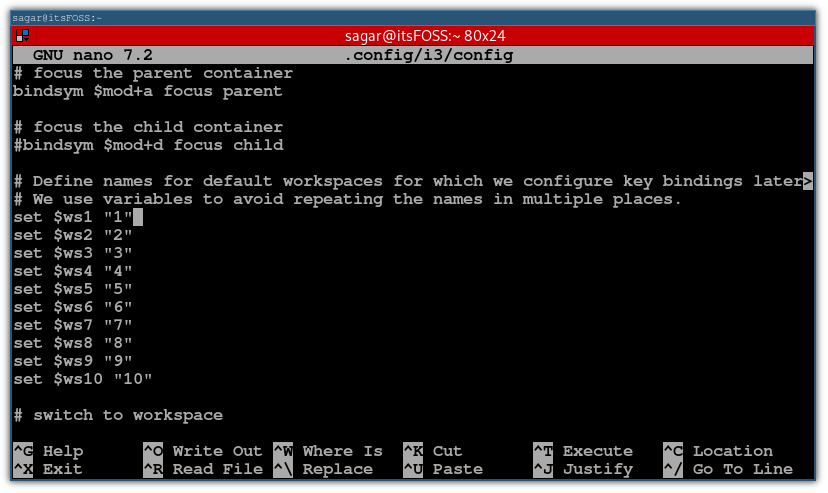
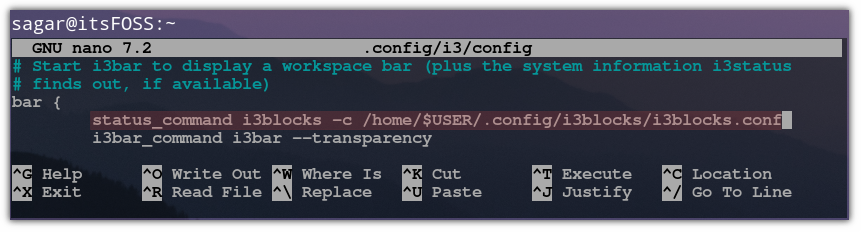
安装完成后,打开配置文件:
1
nano ~/.config/i3/config
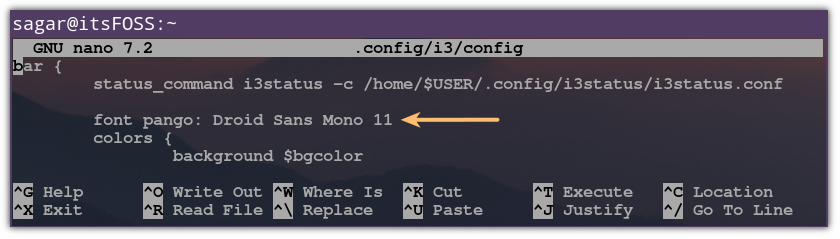
在配置文件中,找到 font pango:monospace 8 这一行,这是默认字体。
找到那行后,添加字体名称和大小,如下所示:
1
font pango:Ubuntu Regular 14
然后,使用 Mod + Shift + r 重新启动窗口管理器,这样就完成了工作:
在 i3 窗口管理器中分配应用程序到工作区
在给工作区命名之后,你会想要将特定的软件分配到相应的工作区中。
例如,如果我将第二个工作区命名为 “Firefox”,那么我只想在该工作区中使用 Firefox。
那么要如何实现呢?
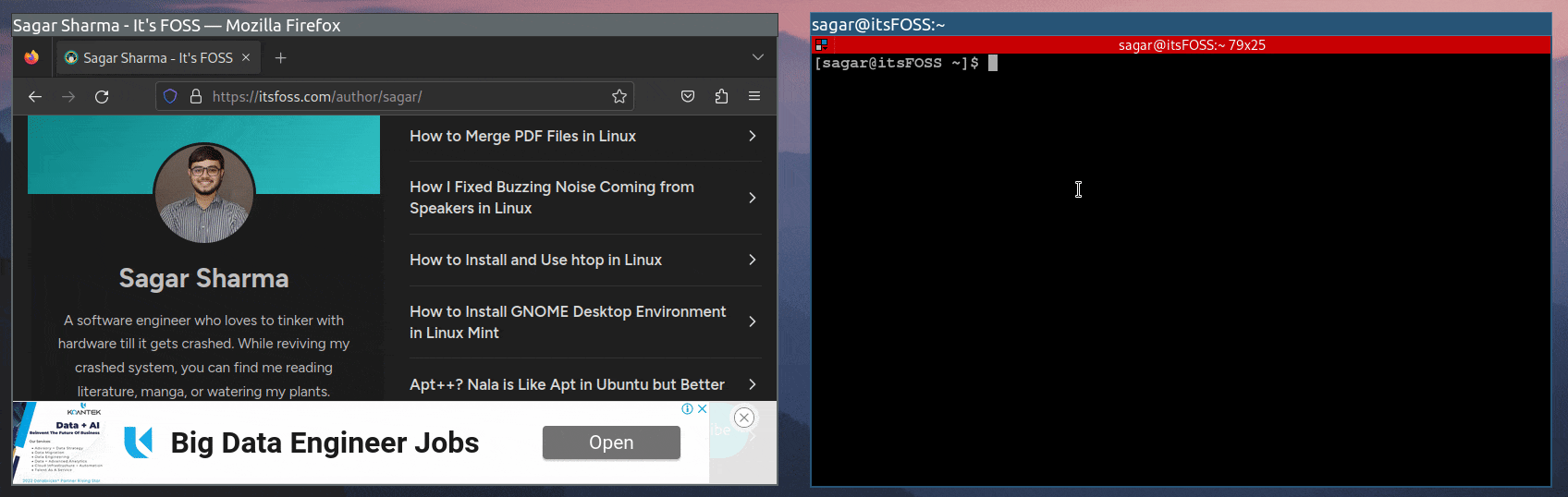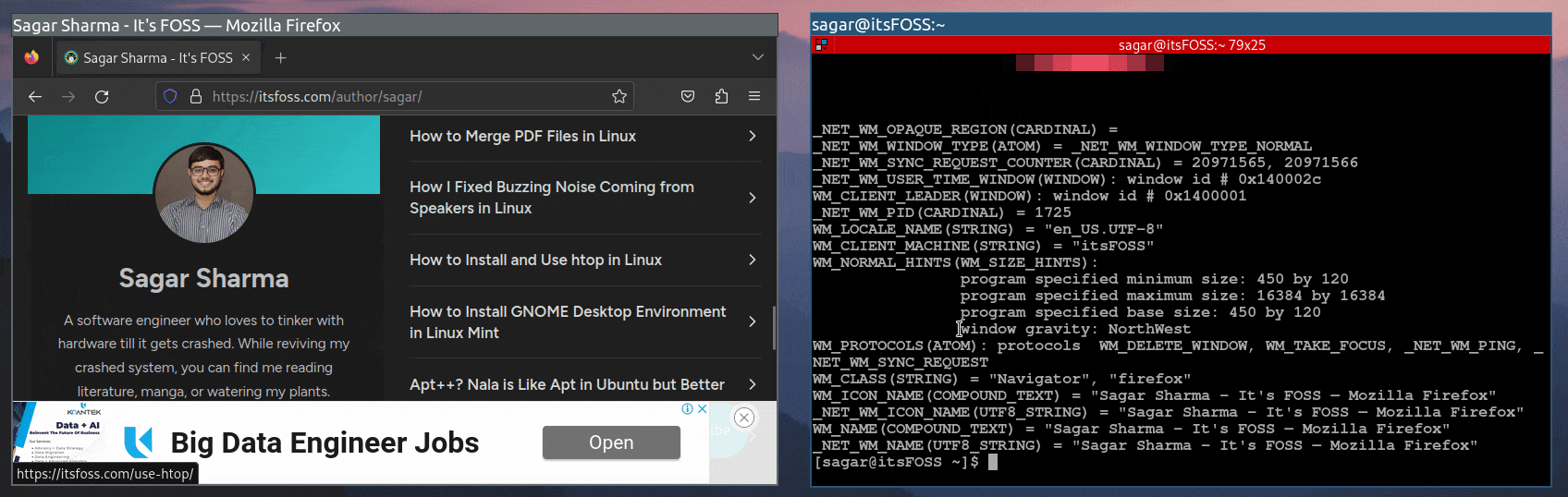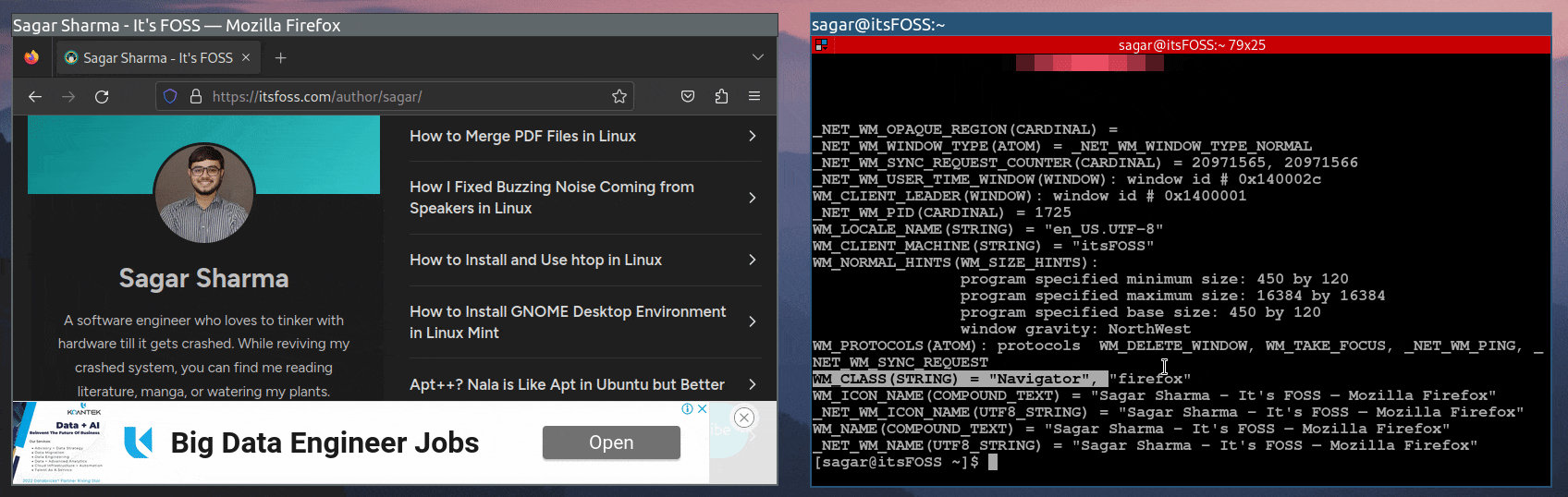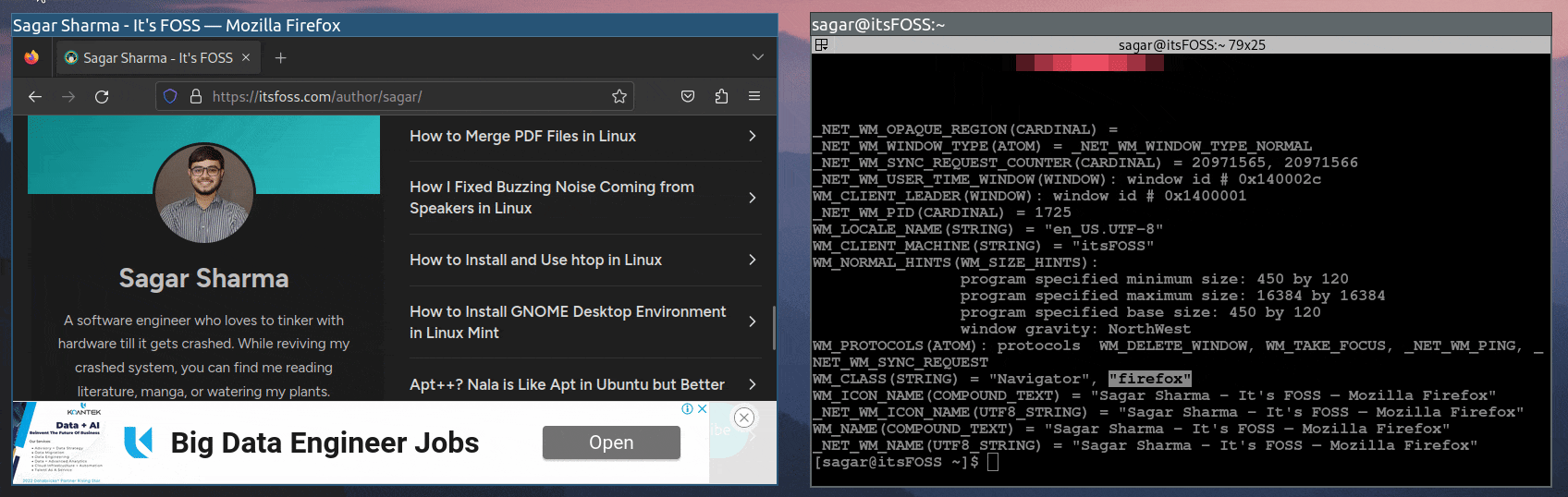
为了做到这一点,你需要找到每个要分配的应用程序的类名。
听起来复杂? 让我告诉你如何做。
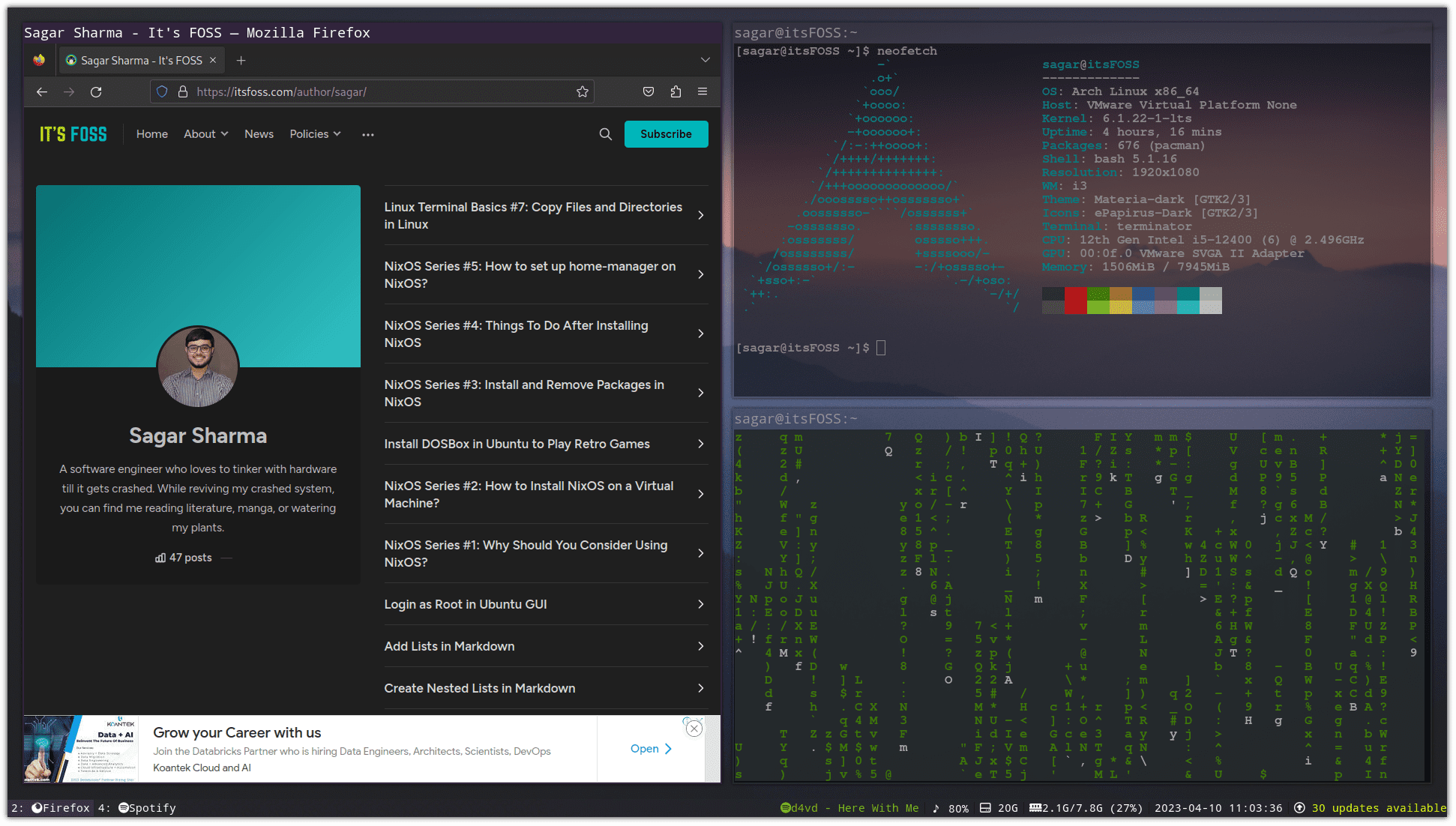
首先,将应用程序和终端并排打开。例如,在这个例子中,我将 Firefox 和终端并排打开:
现在,在终端中执行 xprop 命令,它会改变鼠标指针的形状:
1
xprop
接下来,将鼠标悬停在应用程序上,并在应用程序窗口内的任何位置单击,如图所示:
类名将在以下行的最后一个字符串中找到:
1
WM_CLASS(STRING) = "Navigator", "firefox"
在我的情况下,Firefox 浏览器的类名将是 firefox。
对所有你想要分配到工作区的应用程序重复这个过程。
一旦你知道每个你想要分配到工作区的应用程序的类名,打开配置文件:
1
nano ~/.config/i3/config
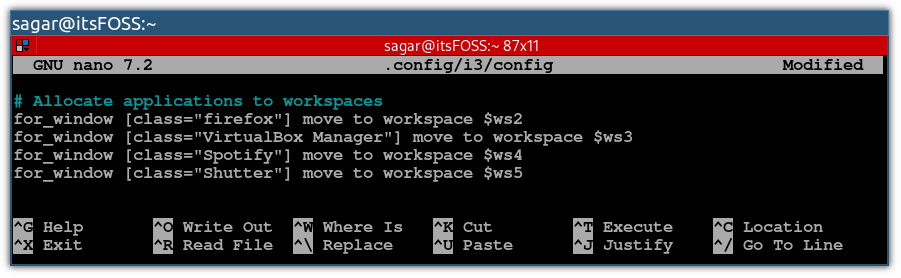
使用 Alt + / 将 nano 定位到文件末尾,并使用以下语法将应用程序分配到工作区:
1 2
# 分配应用到工作区 for_window [class="类名"] move to workspace $[工作区变量]
#!/usr/bin/env sh DIR="${DIR:-$BLOCK_INSTANCE}" DIR="${DIR:-$HOME}" ALERT_LOW="${ALERT_LOW:-$1}" ALERT_LOW="${ALERT_LOW:-10}" # color will turn red under this value (default: 10%)
LOCAL_FLAG="-l" if [ "$1" = "-n" ] || [ "$2" = "-n" ]; then LOCAL_FLAG="" fi
df -h -P $LOCAL_FLAG "$DIR" | awk -v label="$LABEL" -v alert_low=$ALERT_LOW ' /\/.*/ { # full text print label $4 # short text print label $4 use=$5 # no need to continue parsing exit 0 } END { gsub(/%$/,"",use) if (100 - use < alert_low) { # color print "#FF0000" } } '
parser = argparse.ArgumentParser(description='Check for pacman updates') parser.add_argument( '-b', '--base_color', default = _default('BASE_COLOR', 'green'), help='base color of the output(default=green)' ) parser.add_argument( '-u', '--updates_available_color', default = _default('UPDATE_COLOR', 'yellow'), help='color of the output, when updates are available(default=yellow)' ) parser.add_argument( '-a', '--aur', action = 'store_const', const = True, default = _default('AUR', 'False', strbool), help='Include AUR packages. Attn: Yaourt must be installed' ) parser.add_argument( '-y', '--aur_yay', action = 'store_const', const = True, default = _default('AUR_YAY', 'False', strbool), help='Include AUR packages. Attn: Yay must be installed' ) parser.add_argument( '-q', '--quiet', action = 'store_const', const = True, default = _default('QUIET', 'False', strbool), help = 'Do not produce output when system is up to date' ) parser.add_argument( '-w', '--watch', nargs='*', default = _default('WATCH', arg_type=strlist), help='Explicitly watch for specified packages. ' 'Listed elements are treated as regular expressions for matching.' ) return parser.parse_args()
def get_updates(): output = '' try: output = check_output(['checkupdates']).decode('utf-8') except subprocess.CalledProcessError as exc: # checkupdates exits with 2 and no output if no updates are available. # we ignore this case and go on if not (exc.returncode == 2 and not exc.output): raise exc if not output: return []
updates = [line.split(' ')[0] for line in output.split('\n') if line]
return updates
def get_aur_yaourt_updates(): output = '' try: output = check_output(['yaourt', '-Qua']).decode('utf-8') except subprocess.CalledProcessError as exc: # yaourt exits with 1 and no output if no updates are available. # we ignore this case and go on if not (exc.returncode == 1 and not exc.output): raise exc if not output: return []
aur_updates = [line.split(' ')[0] for line in output.split('\n') if line.startswith('aur/')]
return aur_updates
def get_aur_yay_updates(): output = check_output(['yay', '-Qua']).decode('utf-8') if not output: return []
aur_updates = [line.split(' ')[0] for line in output.split('\n') if line]
return aur_updates
def matching_updates(updates, watch_list): matches = set() for u in updates: for w in watch_list: if re.match(w, u): matches.add(u)
#!/usr/bin/env bash if [[ -z "$MIXER" ]] ; then MIXER="default" if command -v pulseaudio >/dev/null 2>&1 && pulseaudio --check ; then # pulseaudio is running, but not all installations use "pulse" if amixer -D pulse info >/dev/null 2>&1 ; then MIXER="pulse" fi fi [ -n "$(lsmod | grep jack)" ] && MIXER="jackplug" MIXER="${2:-$MIXER}" fi if [[ -z "$SCONTROL" ]] ; then SCONTROL="${BLOCK_INSTANCE:-$(amixer -D $MIXER scontrols | sed -n "s/Simple mixer control '\([^']*\)',0/\1/p" | head -n1 )}" fi
# The first parameter sets the step to change the volume by (and units to display) # This may be in in % or dB (eg. 5% or 3dB) if [[ -z "$STEP" ]] ; then STEP="${1:-5%}" fi
NATURAL_MAPPING=${NATURAL_MAPPING:-0} if [[ "$NATURAL_MAPPING" != "0" ]] ; then AMIXER_PARAMS="-M" fi
capability() { # Return "Capture" if the device is a capture device amixer $AMIXER_PARAMS -D $MIXER get $SCONTROL | sed -n "s/ Capabilities:.*cvolume.*/Capture/p" }
volume() { amixer $AMIXER_PARAMS -D $MIXER get $SCONTROL $(capability) }
# gaps set $mode_gaps Gaps: (o)uter, (i)nner, (h)orizontal, (v)ertical, (t)op, (r)ight, (b)ottom, (l)eft set $mode_gaps_outer Outer Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_inner Inner Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_horiz Horizontal Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_verti Vertical Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_top Top Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_right Right Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_bottom Bottom Gaps: +|-|0 (local), Shift + +|-|0 (global) set $mode_gaps_left Left Gaps: +|-|0 (local), Shift + +|-|0 (global) bindsym $mod+Shift+g mode "$mode_gaps"
mode "$mode_gaps" { bindsym o mode "$mode_gaps_outer" bindsym i mode "$mode_gaps_inner" bindsym h mode "$mode_gaps_horiz" bindsym v mode "$mode_gaps_verti" bindsym t mode "$mode_gaps_top" bindsym r mode "$mode_gaps_right" bindsym b mode "$mode_gaps_bottom" bindsym l mode "$mode_gaps_left" bindsym Return mode "$mode_gaps" bindsym Escape mode "default" }
mode "$mode_gaps_outer" { bindsym plus gaps outer current plus 5 bindsym minus gaps outer current minus 5 bindsym 0 gaps outer current set 0
bindsym Shift+plus gaps outer all plus 5 bindsym Shift+minus gaps outer all minus 5 bindsym Shift+0 gaps outer all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_inner" { bindsym plus gaps inner current plus 5 bindsym minus gaps inner current minus 5 bindsym 0 gaps inner current set 0
bindsym Shift+plus gaps inner all plus 5 bindsym Shift+minus gaps inner all minus 5 bindsym Shift+0 gaps inner all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_horiz" { bindsym plus gaps horizontal current plus 5 bindsym minus gaps horizontal current minus 5 bindsym 0 gaps horizontal current set 0
bindsym Shift+plus gaps horizontal all plus 5 bindsym Shift+minus gaps horizontal all minus 5 bindsym Shift+0 gaps horizontal all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_verti" { bindsym plus gaps vertical current plus 5 bindsym minus gaps vertical current minus 5 bindsym 0 gaps vertical current set 0
bindsym Shift+plus gaps vertical all plus 5 bindsym Shift+minus gaps vertical all minus 5 bindsym Shift+0 gaps vertical all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_top" { bindsym plus gaps top current plus 5 bindsym minus gaps top current minus 5 bindsym 0 gaps top current set 0
bindsym Shift+plus gaps top all plus 5 bindsym Shift+minus gaps top all minus 5 bindsym Shift+0 gaps top all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_right" { bindsym plus gaps right current plus 5 bindsym minus gaps right current minus 5 bindsym 0 gaps right current set 0
bindsym Shift+plus gaps right all plus 5 bindsym Shift+minus gaps right all minus 5 bindsym Shift+0 gaps right all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_bottom" { bindsym plus gaps bottom current plus 5 bindsym minus gaps bottom current minus 5 bindsym 0 gaps bottom current set 0
bindsym Shift+plus gaps bottom all plus 5 bindsym Shift+minus gaps bottom all minus 5 bindsym Shift+0 gaps bottom all set 0
bindsym Return mode "$mode_gaps" bindsym Escape mode "default" } mode "$mode_gaps_left" { bindsym plus gaps left current plus 5 bindsym minus gaps left current minus 5 bindsym 0 gaps left current set 0
bindsym Shift+plus gaps left all plus 5 bindsym Shift+minus gaps left all minus 5 bindsym Shift+0 gaps left all set 0
Use “{Question} {Answer} {Fundamentals} {Chain of Thought} {Common Mistakes}” five-element training object for each sample. These sample to train a small model called TeacherLM to re-construct others training data to train or fine-tuning larger LLM
所以在这个问题上,我只会选择看他们模型的代码(即 models 文件夹下的内容),然后我只跑通这一个模块的内容。我不会选择去把他们的实验给实现,因为这个过程是个很费时费力的过程,而且有可能还跑不通。由于我用别人的模型的时候,一般都是放在新数据集上运行(如果你是在这篇论文的数据集上做实验,那么一般就是直接用别人论文里面的结果,不用自己跑),所以我只用关注于把别人的 model 给运行正常即可。
$ head -n 20 /etc/pacman.d/mirrorlist ## ## Arch Linux repository mirrorlist ## Generated on 2023-02-26 ## ## China Server = https://mirrors.bfsu.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.tuna.tsinghua.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.ustc.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.aliyun.com/archlinux/$repo/os/$arch Server = https://mirrors.cqu.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.hit.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.neusoft.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.nju.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.njupt.edu.cn/archlinux/$repo/os/$arch Server = https://mirror.redrock.team/archlinux/$repo/os/$arch Server = https://mirrors.shanghaitech.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.sjtug.sjtu.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.wsyu.edu.cn/archlinux/$repo/os/$arch Server = https://mirrors.xjtu.edu.cn/archlinux/$repo/os/$arch
在浏览网页时,有时进入一个正常的网站,会莫名被跳转到钓鱼网站,这很有可能是系统 DNS 被污染了,因为常规的 DNS 协议使用的是 udp 明文传输,很容易被攻击者监听并篡改,而各大运营商默认分配的 DNS 是重点的污染对象,想要避免这个问题,就要使用加密的 DNS 协议。
systemd 自带的 systemd-resolved 其实已经支持了加密 DNS 协议,但是目前只支持 DNS-over-TLS,安全性相对较差一些,为了使用其他的加密 DNS 程序,需要禁用这个服务 sudo systemctl disable systemd-resolved.service --now。我选择的软件是 dnscrypt-proxy,支持一些最新的加密 DNS 特性,比如使用 HTTP3 的 DNS-over-HTTPS 协议,具体配置方法在这里,不再赘述。想要使用其他软件,可以看这里。
加密 DNS 配置完成后,会与远程的加密 DNS 服务器连接,转发 DNS 请求到本地的 53 端口,但系统默认使用上级路由器 dhcp 分配的 DNS 服务器。想要修改系统默认使用的 DNS 服务器,最直接的方法是编辑 /etc/resolv.conf,在最顶部添加一行 nameserver 127.0.0.1,这样就能默认使用本地 DNS 服务器了,但问题是很多网络管理程序,包括 NetworkManager 都会修改这个文件,所以在重启后 /etc/resolv.conf 很有可能会变回默认。所以使用 NetworkManager 时,更有效的方法是编辑 NetworkManager 的配置文件,编辑 /etc/NetworkManager/conf.d/dns-servers.conf:
1 2
[global-dns-domain-*] servers=127.0.0.1
之后重启服务 sudo systemctl restart NetworkManager.service,这样无论连接什么网络,系统都会默认使用本地的 DNS 服务器了。
另外 Chromium 和 Firefox 浏览器都已经支持了加密 DNS,所以也可以在浏览器对应的配置项开启加密 DNS,这样加密 DNS 将只对浏览器生效。
随机 MAC 地址
NetworkManager 还有一个特性就是随机 MAC 地址,开启之后可以增加安全性,NetworkManager 默认开启了在 wifi 扫描时随机 MAC 地址,想要配置随机 MAC 地址,可以编辑 /etc/NetworkManager/conf.d/rand_mac.conf:
Arch Linux 在笔记本平台相比于 Windows 和其他功能齐全的 Linux 发行版一个比较大的劣势就是续航较差,因为其默认并没有为笔记本续航做优化。
而 Linux 平台笔记本续航优化的软件,最为人熟知且被最多人推荐的是 TLP,并且已经被很多发行版预装,这个软件支持很多设备的省电模式优化,如 CPU、无线网络、蓝牙、硬盘等等,配置好了的话可以大大延长笔记本的续航时间。但是这个软件在我的笔记本上运行似乎有些问题,在断开电源后一段时间后外接键盘会不能用,这大概是 USB 自动休眠的问题,但就算我在配置文件中禁用了 USB 自动休眠,问题也没解决。并且 TLP 默认对省电模式的性能限制有点狠,CPU 无法睿频,导致在电池模式下干什么事情都挺卡的。因为我的使用情况大部分时间笔记本都连着电源,所以续航不太敏感,所以我就一直没有装 TLP。
 引言
引言